Webサイト制作 SEO対策 システム関連 XMLサイトマップ(sitemap.xml)を毎日自動で最新に!自動生成に加えて自動更新するプログラムを開発してみた
-
 開発グループ 古川
開発グループ 古川
- 2021.07.14
こんにちは。制作部開発グループの古川です。
Webサイト制作後のGoogle Search Console(サーチコンソール)へのサイト登録に欠かせないのが、
XMLサイトマップ(sitemap.xml)です。
これまでXMLサイトマップ(sitemap.xml)の作成は、
無料ツールを利用させて頂いておりました。
しかしながら、ページを追加・削除するたびに作り直すのは大変で、
手間が掛かる作業でした。
この作業を自動化できないか、という声が社内に上がっていたため、
今回、自動生成するプログラムを開発いたしました。

XMLサイトマップ(sitemap.xml)とは
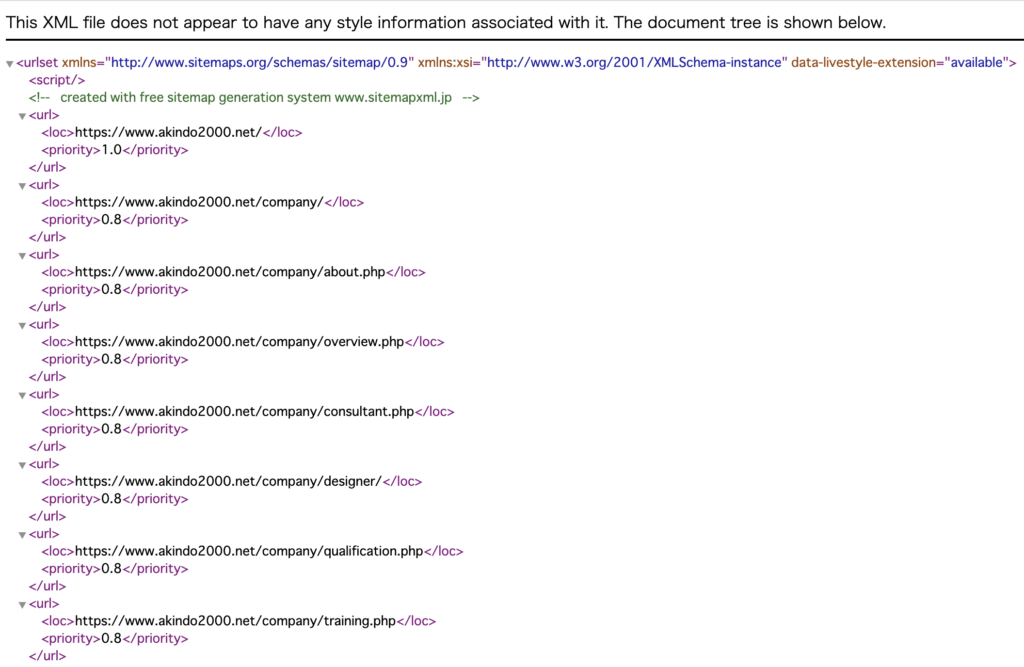
XMLサイトマップ(sitemap.xml)とは、
検索エンジンにクロールしてほしいURLと各URLに関する追加のメタデータ(最終更新日、更新頻度、重要度)を、
一覧表示するXMLファイルです。
XMLサイトマップ(sitemap.xml)のメリット
XMLサイトマップ(sitemap.xml)をサーバー上に設置することで、
検索エンジンのクローラーにサイト内の構造やコンテンツを早く正確に伝えることができます。
追加・更新した画面の情報をXMLサイトマップ(sitemap.xml)に記載すると、
より早く検索エンジンにインデックスされ、検索順位に反映されます。
検索エンジンにインデックスされていないページの有無を把握することができます。
インデックスされていない画面は何かしらの違反がある場合があるため、早めに対応をしないと、WEBサイト全体に悪影響を及ぼしてしまいます。
XMLサイトマップ(sitemap.xml)を使用することで、検索順位を上げられるわけではありませんが、
間接的にSEOに貢献することが出来ます。
XMLサイトマップ(sitemap.xml)の実装方法
作成したコード
 https://www.php.net/manual/ja/class.domdocument.php
https://www.php.net/manual/ja/class.domdocument.php
xmlファイルの生成は、DOMDocumentを使用しました。
こちらのファイルを毎日0時にCronで定期実行を行います。
※再帰処理をするため、ループ回数は1000回までとしています。
※現時点ではGoogleはpriorityの値を使用していません。
サイト内には、様々なリンク表記(「./」「../」「/sampledir/」etc.)があり、
それらを正しく「https://~」(または「https://~」)に正規化するのが難しかったです。
設定
- TOPページの設定(末尾「/」は必須)
define(“HOMEPAGE”, “最上位のアドレス”); - ドキュメントルートの絶対パス(末尾「/」は必須)
define(“DOCUMENT_ROOT”, “ドキュメントルートの絶対パス”); - 出力するXMLサイトマップのファイルパス
define(“DOCUMENT_ROOT”, “出力するXMLサイトマップのファイルパス”); - その他設定
除外する拡張子、ファイル名、ディレクトリ等(上記コードを参照)
アクセス制限
ブラウザからのアクセスを制限するため、.htaccessでアクセス制限を設定しています。
Order allow,deny
Deny from all
まとめ
自社サイトに実装したところ、全てのページがインデックスされ、
自動でXMLサイトマップ(sitemap.xml)を生成することができました。
さらに、毎日0時に自動更新してくれるため、
ページの追加や削除があった場合にも、
最新情報をクローラーに伝えることができます。
今回作成したプログラムは、HTMLサイトのみ対応可能なため、
今後は、HTMLとWordpressが混在したサイトに対応したツールの開発をしていきたいと思います。
CMAブログをGoogle検索で見つけやすくしたい方はこちら

おすすめの記事





おすすめタグ
- PHP
- Google my map
- Instagram広告
- 初心者
- カスタマイズ
- サイズパラメーター
- UI
- 中小企業SFA
- PowerPoint
- CSS
- 創業記念日
- クリック率
- 自作パソコン
- ASP
- レクタングルバナー
- UX
- SFA
- Figmaデザイン
- 動画制作
- レクリエーション
- TLS
- PC組み立て
- IE
- アセット生成
- Adobe Stock
- 中小企業向けSFA
- グリッドビュー
- AMP
- Adobe XD
- Chrome
- Google Search Console
- コーディング
- タスクランナー
- アンチックフォント
- AVIF
- バージョン管理
- 広告
- ワイヤーフレーム
- 保護されていない通信
- XMLサイトマップ
- モダンブラウザ
- gulp.js
- Adobe Express
- AdobeExpress
- Edits
- 構造化マークアップ
- Google for jobs
- Transport Layer Security
- shopify
- gap
- node.js
- Webマーケティング
- Canva
- 採用サイト
- HTML5広告
- Googleしごと検索
- HowTo
- ECサイト
- gridレイアウト
- WebP画像
- デジタルマーケティング
- 画像作成
- 楽天市場
- Google Chrome
- 撮影
- ハウツー
- ショッピングサイト
- object-fit
- 楽天GOLD
- 文字コード
- ChatGPT
- EC
- videoタグ
- iPad
- 構造化データ
- ショッピファイ
- aspect-ratio
- スマートフォン用新店舗トップページ
- 符号化文字集合
- 業務効率化
- ChatGPT広告
- 動画
- 一眼レフカメラ
- リッチリザルト
- Shopify使い方
- any-hover
- Threads(スレッズ)
- Unicode(ユニコード)
- SNS
- AI
- 動画広告
- 写真
- ノンデザイナー
- WebP
- docker
- 未経験
- AdobeMAX
- GoogleMapsPlatform
- リモート
- 文字
- wordpress
- Photoshop
- Adobe Firefly
- 新人デザイナー
- AdobeFirefly
- スピードアップデート
- ウェブサイト翻訳
- デザイン
- リモートワーク
- クラウドドキュメント
- 画像生成AI
- CMS
- バリアブルフォント
- PageSpeed Insights
- iPhone
- フォント
- remotework
- ディスプレイ広告
- 生成塗りつぶし
- 絞り込み検索
- 生成AI
- SSL
- Facebook Audience Network
- Core Web Vitals
- ECcube
- スマートオブジェクト
- 生成拡張
- カレンダー
- Gemini
- HTML
- Zapier
- Facebook広告
- 自作PC
- プラグイン
- 画質パラメーター
- Adobe MAX Japan 2023
- ハッシュタグ
- Figma Slides